Abstract
With a quick experiment I wanted to check if the current stable version of Alembic - the "database migrations" companion tool of the SQLAlchemy database abstraction layer and ORM - could be used with the brand new major version (still in Beta at the time of writing) of SQLAlchemy.
As someone who cannot code without type annotations, I find it quite exciting to see that the Python ecosystem seems to be going more and more towards "strongly type-hinted" packages, the same way it's been happening in the JavaScript world with TypeScript during the last few years.
The upcoming major version of SQlAlchemy - quite a major tool, with its 60 millions downloads per month! - is bringing a very modern way to define Models, based on Python type hints.
I mean... look at the beauty of these fields declaration - especially for the fields
that don't need anything more than just a str or int Python type hint 👌
import datetime as dt
from sqlalchemy import String, SmallInteger, func
from sqlalchemy.orm import DeclarativeBase, Mapped, mapped_column
class Base(DeclarativeBase):
pass
class GameResult(Base):
__tablename__ = "game_results"
id: Mapped[int] = mapped_column(primary_key=True)
player_north_name: Mapped[str] = mapped_column(String(50))
player_south_name: Mapped[str] = mapped_column(String(50))
outcome: str # just a type hint ♥
winner_name: Mapped[str | None] = mapped_column(String(50))
deadwood_value: Mapped[int] = mapped_column(SmallInteger)
winner_score: int | None # ditto ♥
created_at: Mapped[dt.datetime] = mapped_column(insert_default=func.now())
This code comes from the very complete 📚 changelog of the 2.0.0b3 Beta release:
Database migrations management
As I can't live my backend developer life without a database migrations machinery (whether it's Django's excellent one, or before that Doctrine's, Rails', or Zend Framework's also great migrations systems), I cannot give a try to that version of SQLAlchemy without migrations. 😅
My issue was that even if I can start fiddling with SQLAlchemy 2 right away by installing the Beta release, there is nothing on its migration companion (Alembic, also maintained by the folks behind SQLAlchemy) saying that it does work with this new version 🤔
But who knows, maybe the "metadata" part of the SQLAlchemy API hasn't been changed so much with this 2.0 version - which would allow me to use the current stable version of Alembic with this shiny new release of SQLAlchemy? Let's give it a shot! :fingers_crossed:
Setting up a "SQLAlchemy 2 + Alembic" test project
Common Python project setup
As always, I'll start with a new virtual environment, with an up-to-date version of Pip and Poetry ready to serve:
$ mkdir sqlalchemy2-test
$ cd sqlalchemy2-test/
$ pyenv shell 3.10.4
$ python -m venv .venv
$ venv # my shell alias for `source .venv/bin/activate`
(.venv) $ pip install -U pip poetry
(.venv) $ poetry init
Installing and configuring SQLAlchemy & Alembic
Right, now let's install the Beta version of SQLAlchemy 2, as well as the stable version of Alembic:
Then, according to Alembic's tutorial we have to run an initalisation command:
This command creates a alembic.ini at the root of my project, as well as an alembic/ folder
at the same level, with some files pretty much ready to be used as is.
For demonstration purpose I'll just create a models.py file at the root of my project,
and copy-paste the nicely type-hinted User and Address models from the changelog in that file.
sqlalchemy2-test/
├── alembic/
│ ├── versions/
│ ├── env.py # Alembic Python config - using data from the INI file
│ ├── README
│ └── script.py.mako # the template for generated migrations
├── alembic.ini # Alembic INI config
├── models.py # my SQLAlchemy models definition
├── poetry.lock
└── pyproject.toml
The next step is to tell Alembic where the SQLAlchemy metadata are.
This is done in the alembic/env.py file:
# file: alembic/env.py
# add your model's MetaData object here
# for 'autogenerate' support
from models import Base
target_metadata = Base.metadata # and that's it! 🙂
Hard-coded database URL in the INI file? Meh 😄
I could have left the alembic.ini and the alembic/env.py files as is (that's where Alembic
gets its settings from), however I noticed that the URL of the database is hard-coded
in the INI file - which is something I'm not a big fan of.
# file: alembic.ini
# N.B. The generated file is nicely documented 👌, but for the sake of brevity
# I'll strip the comments from this extract :-)
[alembic]
script_location = alembic
prepend_sys_path = .
sqlalchemy.url = driver://user:pass@localhost/dbname
[loggers]
; etc
In most modern Web projects the URL of the database we're interacting with comes from an environment variable
(usually DATABASE_URL, but it can have any name really), so one can deploy their project on any number of environments
and point to different databases on each of them, simply by setting the value of that variable.
I really want to be able to use a DATABASE_URL environment variable, rather than relying on some hard-coded data in an INI file!
But wait a minute... 🤔
This alembic/env.py being a plain Python file, surely there must be a way for me to get the database URL injected
from an environment variable, just by adding a tiny bit of Python logic? :fingers_crossed:
Using an DATABASE_URL environment variable to set up the database
I'm not familiar at all with the content of that alembic/env.py file, but from what I understand
of if after having skimmed through it... 👓
It seems that the content of the INI file - where the hard-coded database URL is - is used in 2 locations:
# file: alembic/env.py
... # various stuff here
def run_migrations_offline() -> None:
url = config.get_main_option("sqlalchemy.url")
context.configure(
url=url,
target_metadata=target_metadata,
literal_binds=True,
dialect_opts={"paramstyle": "named"},
)
with context.begin_transaction():
context.run_migrations()
def run_migrations_online() -> None:
connectable = engine_from_config(
config.get_section(config.config_ini_section),
prefix="sqlalchemy.",
poolclass=pool.NullPool,
)
with connectable.connect() as connection:
context.configure(connection=connection, target_metadata=target_metadata)
with context.begin_transaction():
context.run_migrations()
... # various stuff there too
Ok, so in one place it seems that we extract the database URL directly from the INI config
(url = config.get_main_option("sqlalchemy.url")), while in the other one we pass the whole config
to SQLAlchemy (config.get_section(config.config_ini_section)).
Let's see if I can inject the value of a DATABASE_URL environment variable to replace the hard-coded one,
with the following changes (highlighted):
# file: alembic/env.py
import os
SQLALCHEMY_URL = os.environ.get("SQLALCHEMY_URL")
# And then, I can adapt the previous code:
def run_migrations_offline() -> None:
url = SQLALCHEMY_URL or config.get_main_option("sqlalchemy.url")
context.configure(
url=url,
target_metadata=target_metadata,
literal_binds=True,
dialect_opts={"paramstyle": "named"},
)
with context.begin_transaction():
context.run_migrations()
def run_migrations_online() -> None:
ini_config = config.get_section(config.config_ini_section)
if SQLALCHEMY_URL:
ini_config["sqlalchemy.url"] = SQLALCHEMY_URL
connectable = engine_from_config(
ini_config,
prefix="sqlalchemy.",
poolclass=pool.NullPool,
)
with connectable.connect() as connection:
context.configure(connection=connection, target_metadata=target_metadata)
with context.begin_transaction():
context.run_migrations()
And now, let's try to generate an automatic database migration, from the User and Address models I've copy-pasted from the SQLAlchemy 2 changelog! :fingers_crossed:
Generating an automatic migration from the SQLAlchemy models
(.venv) $ SQLALCHEMY_URL=sqlite+pysqlite:///db.sqlite3
(.venv) $ alembic revision --autogenerate -m "add Users and Address"
Hey, it seems to work!
Now I have a alembic/versions/694d8b4caa20_add_users_and_address.py file:
"""add Users and Address
Revision ID: 694d8b4caa20
Revises:
Create Date: 2022-11-03 20:50:27.894030
"""
from typing import Sequence, Union
from alembic import op
import sqlalchemy as sa
# revision identifiers, used by Alembic.
revision: str = "490d7e8880e6"
down_revision: Union[str, None] = None
branch_labels: Union[str, Sequence[str], None] = None
depends_on: Union[str, Sequence[str], None] = None
def upgrade() -> None:
# ### commands auto generated by Alembic - please adjust! ###
op.create_table(
"game_results",
sa.Column("id", sa.Integer(), nullable=False),
sa.Column("player_north_name", sa.String(length=50), nullable=False),
sa.Column("player_south_name", sa.String(length=50), nullable=False),
sa.Column("outcome", sa.Integer(), nullable=False),
sa.Column("winner_name", sa.String(length=50), nullable=True),
sa.Column("deadwood_value", sa.SmallInteger(), nullable=False),
sa.Column("winner_score", sa.Integer(), nullable=True),
sa.Column("created_at", sa.DateTime(), nullable=False),
sa.PrimaryKeyConstraint("id"),
)
# ### end Alembic commands ###
def downgrade() -> None:
# ### commands auto generated by Alembic - please adjust! ###
op.drop_table("game_results")
# ### end Alembic commands ###
Applying the migrations
Last but not least... Let's try to apply that database migration!
I can see that I now have a db.sqlite3 that doesn't seem empty...
Let's open with a database editor:
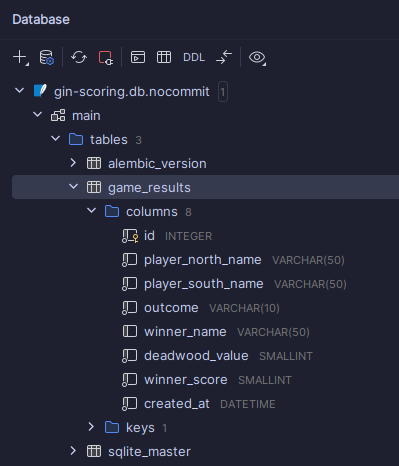
Bingo! 🎉
Can I also revert the migration, and then re-apply it?
(.venv) $ alembic alembic downgrade -1
# I can see in the database that the latest migration was indeed reverted!
# Let's re-apply it:
(.venv) $ alembic upgrade head
# It works! 🙂
Note
If you want to have a look, the whole toy project (with an additional handy Makefile) can be found there:
Closing notes
With this quick experiment I was able to check that the current stable version of Alembic can well and truly be used with the new major version of SQLAlchemy, which is neat. 👌
It's so nice to see major packages like SQLAlchemy opting for type-hinted code! As for me, I joined the world of Python because type hints were starting to be a thing there - so seeing things like that really please me!
Exciting times! 🙂